我用来扒网站静态页面得,只能扒HTML,而且有一些资源没办法搞下来,这个具体什么情况自己再手动搞一下就好了。。。
提供了一个思路,麻烦大佬别找我麻烦,下载得文件已经删除。同时,建议尊重知识产权哈。
超级简单得wget命令应用,也麻烦大佬们轻喷哈。
具体事例:
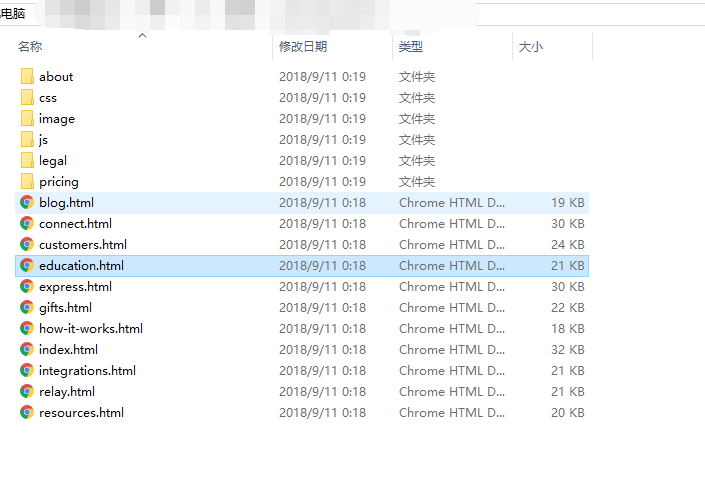
需要下载某个目录下面的所有文件。命令如下
wget -c -r -np -k -L -p www.xxx.org/pub/path/在下载时。有用到外部域名的图片或连接。如果需要同时下载就要用-H参数。
wget -np -nH -r --span-hosts www.xxx.org/pub/path/-c 断点续传
-r 递归下载,下载指定网页某一目录下(包括子目录)的所有文件
-nd 递归下载时不创建一层一层的目录,把所有的文件下载到当前目录
-np 递归下载时不搜索上层目录,如wget -c -r www.shenqiyu.com/pub/path/
没有加参数-np,就会同时下载path的上一级目录pub下的其它文件
-k 将绝对链接转为相对链接,下载整个站点后脱机浏览网页,最好加上这个参数
-L 递归时不进入其它主机,如wget -c -r www.shenqiyu.com/
如果网站内有一个这样的链接:
www.shenqiyu.com,不加参数-L,就会像大火烧山一样,会递归下载www.shenqiyu.com网站
-p 下载网页所需的所有文件,如图片等
-A 指定要下载的文件样式列表,多个样式用逗号分隔
-i 后面跟一个文件,文件内指明要下载的URL

发表评论: